What if AI could teach itself to reason without our help? Hint-DeepSeek-R1
DeepSeek-R1 not only challenges the status quo but sets a new standard for reasoning performance, opening doors to a future where AI truly thinks for itself.

Imagine this: you’re building a complex AI system, but every time it encounters a new challenge, it needs you to hold its hand, feed it data, and guide its learning. Frustrating, right? Now, what if that AI could not only learn from scratch but evolve its reasoning abilities autonomously?
In recent years, advancements in AI have brought us closer to bridging the gap toward Artificial General Intelligence (AGI). Yet, one burning question remains: how can we empower these models to independently scale their reasoning capabilities without relying heavily on supervised data? DeepSeek-R1—a model that redefines what’s possible with reinforcement learning and self-evolution. DeepSeek-R1 not only challenges the status quo but sets a new standard for reasoning performance, opening doors to a future where AI truly thinks for itself.
Reinforcement Learning: The Power Behind DeepSeek-R1’s Evolution
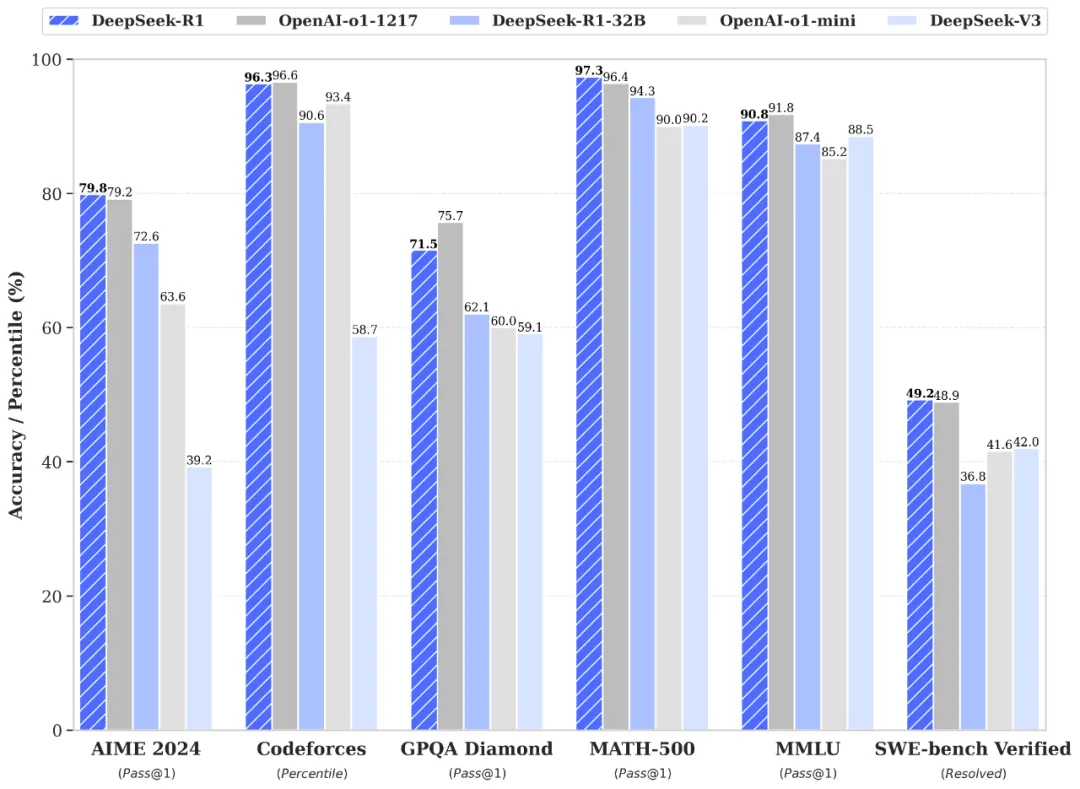
DeepSeek-R1 is a big step forward in making AI models better at reasoning without needing tons of labeled data. It all starts with a base model called DeepSeek-V3-Base, which was improved using a technique called reinforcement learning (RL). Think of RL like teaching the model through trial and error until it gets really good at solving problems. This process created a version called DeepSeek-R1-Zero, which showed amazing improvements. For example, its performance on a tough test (AIME 2024) jumped from just 15.6% correct answers to 71%. And when it combined multiple answers to decide the best one, it hit 86.7%, matching some of the best AI models out there, like OpenAI’s top models.
But there was still room to improve. DeepSeek-R1-Zero sometimes struggled with clarity in its responses and mixed up languages. To fix these issues and make the model even stronger, the team created DeepSeek-R1. They started by giving the model a small set of high-quality data to fine-tune it, then trained it again with more RL to focus on reasoning. They also generated new data from the model itself to fine-tune it further, combining examples from different tasks like answering questions, writing, and even self-awareness prompts. The result? DeepSeek-R1 reached the same level as some of the best AI models while being more efficient and reliable. The team didn’t stop there—they took what they learned and applied it to smaller models, making them faster and just as powerful, setting new records for AI reasoning performance
Fine-Tuning for Precision
Traditionally, supervised fine-tuning (SFT) has been used to train models, but this approach is costly and time-intensive. The study introduces two approaches: DeepSeek-R1-Zero, which uses RL on a basic model without any pre-training data, and DeepSeek-R1, which starts with a small amount of high-quality training data before applying RL. Both methods aim to enhance reasoning abilities efficiently, with DeepSeek-R1 achieving faster convergence and better results due to its initial pre-training.
Reinforcement learning here is guided by a unique algorithm called Group Relative Policy Optimization (GRPO), which simplifies the process by avoiding a costly evaluation system and instead compares multiple responses to optimize the model. Rewards play a crucial role in this process. Accuracy rewards ensure the AI provides correct answers, while format rewards encourage clear and structured responses. These techniques allow the model to evolve and improve its reasoning capabilities over time without extensive supervised data.
The study demonstrates that DeepSeek-R1-Zero achieves remarkable performance on reasoning tasks purely through RL, achieving a success rate of 71% on benchmarks like AIME 2024. DeepSeek-R1 builds on this by incorporating a small amount of supervised data (cold-start data) before applying RL, resulting in better performance and clearer, more user-friendly outputs. The research also highlights the model’s ability to “self-evolve,” showing behaviors like reflecting on earlier steps and exploring alternative solutions, which emerged naturally during training.
Combining RL and Distillation
To make these improvements accessible to smaller, more efficient models, the study uses a process called distillation. By transferring the knowledge from DeepSeek-R1 to smaller models like Llama and Qwen, these smaller models can perform well on reasoning tasks without needing the full RL training. This makes the advancements practical for a broader range of applications.
This work shows that RL can significantly enhance reasoning capabilities, even without extensive supervised data. Combining RL with small-scale pre-training improves efficiency and readability, while distillation methods make these advancements usable for smaller models. This approach paves the way for more autonomous, adaptive, and resource-efficient AI systems.
Pricing for DeepSeek-R1
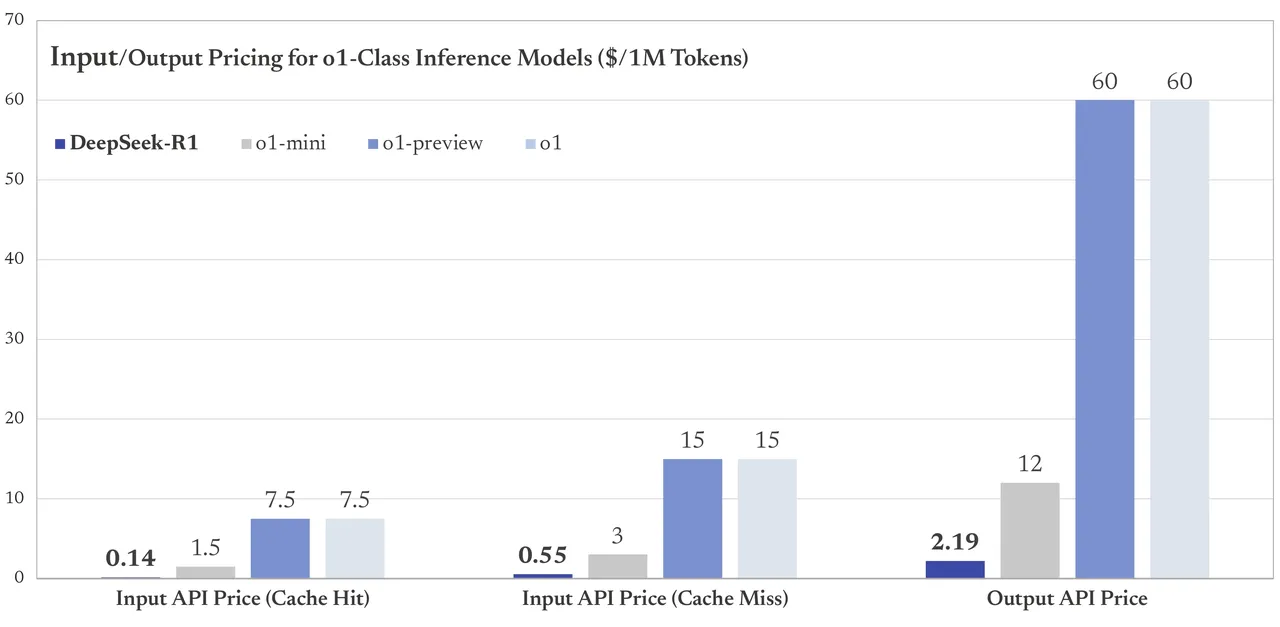
DeepSeek-R1 offers affordable pricing, making it accessible for a wide range of users. The model is available via API with flexible pricing based on token usage. For input tokens, the cost is $0.14 per million tokens for cache hits and $0.55 per million tokens for cache misses. For output tokens, the cost is $2.19 per million tokens. These competitive rates ensure that users can leverage the powerful reasoning capabilities of DeepSeek-R1 for tasks like math, code, and logical reasoning at a reasonable price. With its MIT license, the model is open for fine-tuning and distillation, allowing both individuals and businesses to integrate and customize it for their needs. The open-source nature and transparent pricing make DeepSeek-R1 a valuable resource for the AI community.
References
