Exploring Multimodal AI
An in-depth look at the rapidly growing field of multimodal AI, its applications, benefits, challenges, and impact on various industries.

Multimodal AI is rapidly transforming the landscape of artificial intelligence, redefining how machines interact with the world. Imagine AI systems capable of perceiving and interpreting data through multiple senses—processing text, audio, images, and video all at once. This convergence enables AI to achieve a new level of understanding, producing interactions that feel more seamless, intuitive, and even human like. In this blog, we’ll explore the core components, industry changing applications, advantages, and challenges of this technology that’s reshaping the future of AI.
Key Aspects of Multimodal AI
Multimodal AI combines different modalities (text, audio, images, and video) to create a richer, more holistic understanding of data, much like human cognition. This integration allows AI to:
- Process multiple data types concurrently.
- Interpret and connect different data inputs.
- Generate outputs in various formats.
Through these capabilities, multimodal AI brings about a paradigm shift in how AI can interact with complex, real-world information.
Applications and Benefits
Multimodal AI is revolutionizing numerous industries:
- Customer Service: Analyzes a customer’s voice tone, facial expressions, and written words, enabling more personalized interactions.
- Document Processing: Automates the structuring of data from various document types using optical character recognition and natural language processing.
- Retail: Personalizes shopping experiences by analyzing purchase history, browsing behavior, and social media activity.
- Security: Enhances threat detection by analyzing both video and audio data.
- Manufacturing: Monitors equipment with visual and sensor data to predict maintenance needs.
Popular Multimodal AI Models
Here are some leading multimodal AI models in 2024:
- GPT-4V (OpenAI): Processes text, images, and audio.
- Claude 3 (Anthropic): Known for high accuracy in processing text and images.
- Gemini (Google): Integrates text, images, audio, and video.
- DALL-E 3 (OpenAI): Specialized in text-to-image generation.
These models reflect the wide range of data types that multimodal AI can handle, each excelling in different applications.
Impact and Future Outlook
The multimodal AI market, valued at $1.2 billion in 2023, is projected to grow at a CAGR of over 30% from 2024 to 2032. This rapid growth signals the increasing adoption of multimodal AI across industries. As multimodal AI evolves, it promises to make technology interactions more intuitive and context-aware, inching closer to human-like communication and perception.
Advantages Over Traditional AI
Multimodal AI introduces several key advantages over traditional, unimodal AI systems:
- Data Utilization: By processing multiple data types simultaneously, multimodal AI can extract deeper insights, leveraging a more comprehensive view of complex issues.
- Resource Usage: These systems often need less training data by learning from relationships across data types, and they efficiently focus on relevant information from each modality.
- Process Streamlining: Multimodal AI integrates various data types to enhance efficiency, such as in customer service, where it analyzes voice, facial expressions, and text for more accurate responses.
- Accuracy and Robustness: Multimodal systems cross-verify information across different modalities, enhancing reliability and robustness against noise.
- Versatility: Due to its ability to handle various inputs, multimodal AI offers efficient solutions for diverse tasks across industries.
How Multimodal AI Works
Multimodal AI systems integrate and process various types of data inputs simultaneously to provide nuanced, context-aware outputs. Here’s a breakdown of a typical multimodal AI system:
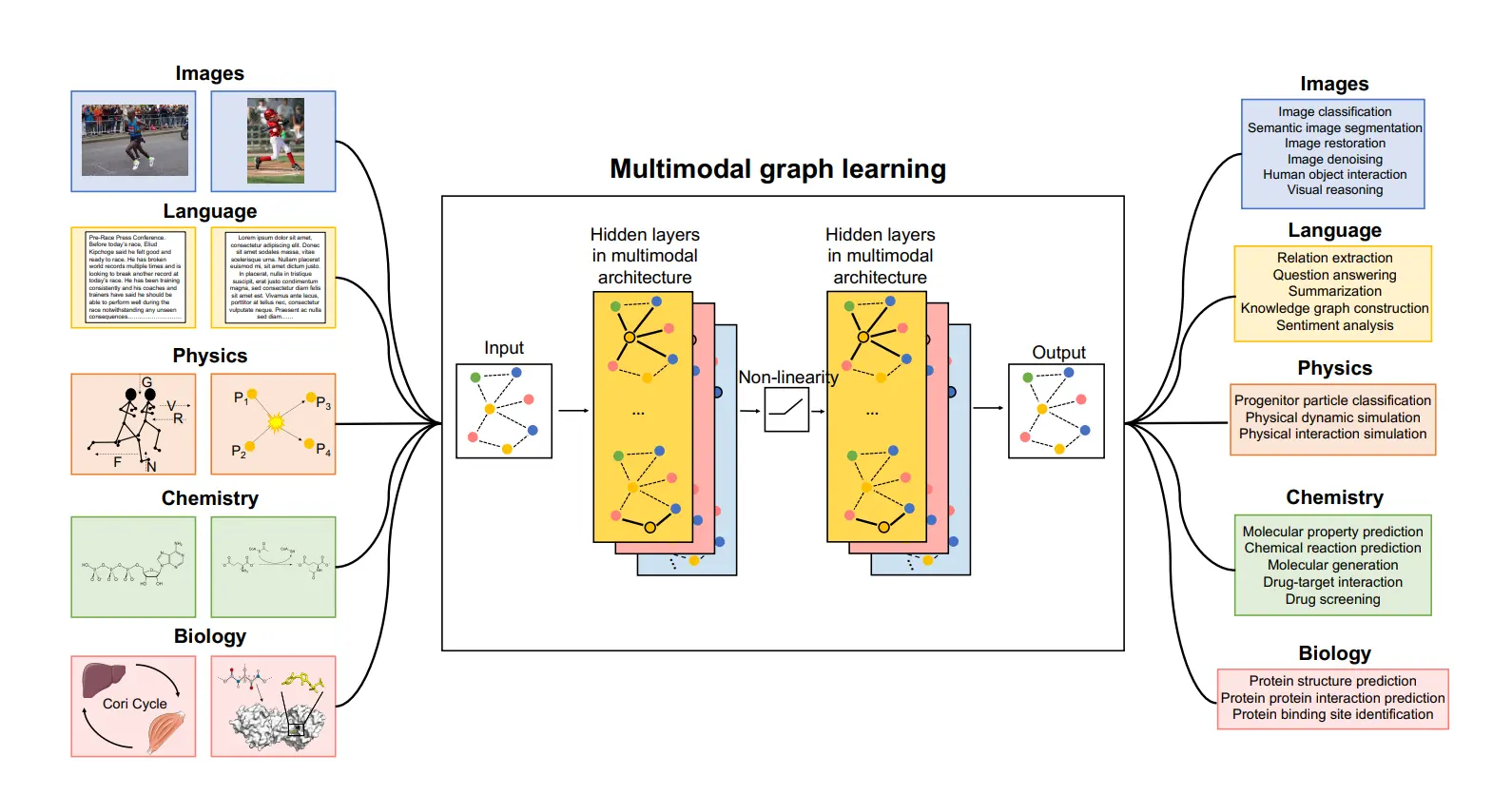
Key Components
- Input Module: Responsible for ingesting different data types (text, images, audio, video), each handled by a specialized neural network.
- Fusion Module: Combines and aligns data from various modalities, enhancing understanding by using transformer models and other data processing techniques.
- Output Module: Generates actionable outputs, such as predictions or content creation.
Data Processing Flow
- Data Collection: Gathers data from multiple sources.
- Preprocessing: Prepares each data type (e.g., text tokenization, image resizing, audio spectrograms).
- Unimodal Encoding: Extracts features using specialized models (e.g., CNNs for images, NLP models for text).
- Fusion: A fusion network creates a unified representation by combining features from each modality.
- Contextual Understanding: Analyzes relationships and importance among modalities.
- Output Generation: Processes the unified representation to produce final outputs, such as classifications or content.
Fusion Techniques
- Early Fusion: Combines raw data at the input level.
- Intermediate Fusion: Processes and preserves modality-specific features before merging.
- Late Fusion: Analyzes each modality separately, merging outputs from each.
Technologies Involved
Key technologies driving multimodal AI include:
- Natural Language Processing (NLP): For speech recognition and text analysis.
- Computer Vision: For image and video analysis.
- Integration Systems: To align, combine, and prioritize data inputs.
- Storage and Compute Resources: To manage data processing and generation.
Through these technologies, multimodal AI achieves a richer, more contextual understanding, closely mimicking human perception and decision-making.
Challenges
While multimodal AI provides significant advantages, it also presents challenges:
- Complexity in Design and Implementation: Combining multiple data types requires sophisticated system design.
- Higher Computational Requirements: Processing multiple modalities demands greater computational resources.
- Data Integration and Alignment: Integrating different data formats and aligning them is challenging but essential for effective multimodal AI.
Despite these challenges, the accuracy and versatility benefits often justify the complexity, particularly for intricate tasks that benefit from multimodal inputs.
Multimodal AI is fundamentally transforming AI’s ability to understand and interact with the world. As these systems continue to evolve, they offer the potential to change how we experience technology, creating more natural and context-aware interfaces across various industries.
Sources
