How Twitter Achieved Real-Time Analytics at Scale
Twitter transitioned from a Lambda Architecture to a Kappa Architecture, revolutionizing real-time event processing for 400 billion daily events

Every day, Twitter processes approximately 400 billion events, generating petabyte-scale data from diverse sources like Hadoop, Kafka, Google Cloud Storage (GCS), and BigQuery. This data fuels critical metrics for ad performance and user engagement services. However, as the demands for real-time insights grew, Twitter faced challenges with its existing infrastructure, including high complexity, data loss, and inefficiencies.
This blog explores Twitter’s transition from the Lambda Architecture to the Kappa Architecture, a move that simplified operations, improved accuracy, and unlocked real-time analytics. We’ll break down what Kappa Architecture is, how Twitter implemented it, and the benefits it unlocked.
What Is the Kappa Architecture?
The Kappa Architecture is a modern approach to handling streaming data, designed to unify real-time and historical data processing on a single technology stack. Unlike the Lambda Architecture, which separates batch and streaming processes, Kappa treats all data as a continuous stream. This unification simplifies the data pipeline while maintaining flexibility and scalability.
Key Features of Kappa Architecture
-
Unified Technology Stack
- Both real-time and historical data processing use the same framework.
- Data is processed as it arrives, enabling seamless analytics.
-
Core Components
- Messaging Engine: Systems like Apache Kafka store incoming data streams.
- Stream Processing Engine: Processes and analyzes the data in near real-time.
- Analytics Database: Stores transformed data for querying and analysis.
-
On-Demand Analytics
- Historical data can be queried ad hoc for rapid insights, eliminating the need for complex batch systems.
Old Architecture: The Lambda Approach
Twitter originally relied on the Lambda Architecture, which combines batch and real-time processing. While effective for certain workloads, this architecture introduced significant challenges.
Workflow
-
Batch Processing:
- Used Scalding on HDFS for hourly processing.
- Results stored in Manhattan, a distributed storage system.
-
Real-Time Processing:
- Leveraged Heron (on Kafka) to process streaming data.
- Results cached in Nighthawk for fast access.
-
Query Service:
- TSAR consolidated data from both systems for customer-facing services.
Challenges
- Data Loss: Back pressure in real-time pipelines caused event loss.
- Latency: Recovering from lags in Heron pipelines was slow.
- Batch Costs: Managing petabyte-scale batch pipelines increased costs and complexity.
Transition to Kappa Architecture
To address these challenges, Twitter adopted the Kappa Architecture, embracing a streaming-only model. This streamlined approach eliminated batch systems while retaining the ability to process historical data through reprocessing streams.
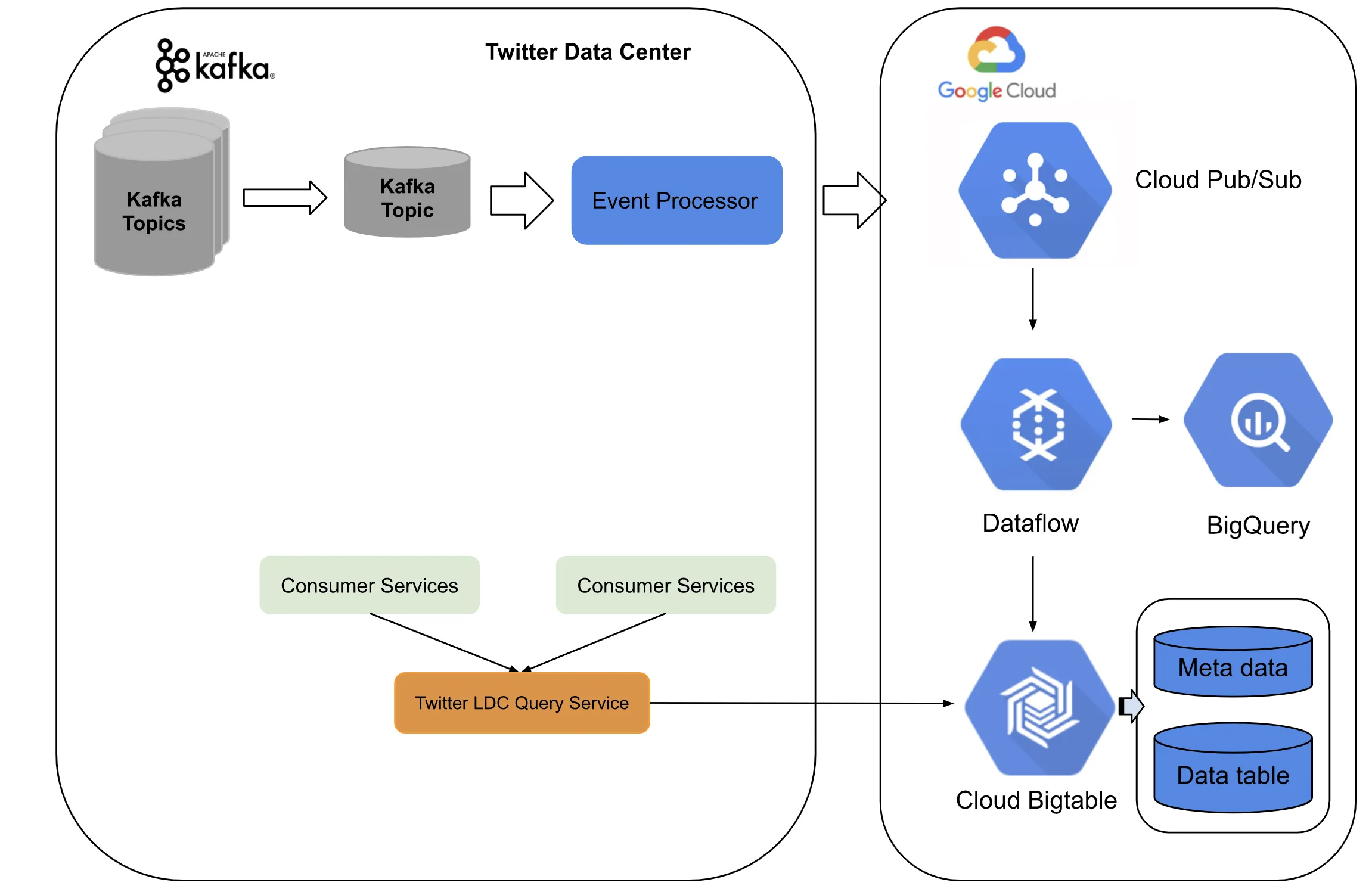
The Kappa Pipeline at Twitter
-
On-Premise: Kafka to PubSub
- Preprocessing pipelines transformed and enriched events, with UUIDs ensuring deduplication.
- Data was published to an internal PubSub system, guaranteeing at-least-once processing.
-
Google Cloud: Dataflow on PubSub
- Real-time deduplication and aggregation were performed using Google Dataflow.
- Processed data was stored in Bigtable for high-throughput queries.
Benefits of Kappa Architecture at Twitter
-
Simplicity
- A single, unified processing pipeline replaced the dual-batch-stream setup.
- Operational overhead was significantly reduced.
-
Flexibility
- Processing logic can be updated and re-applied to historical data streams.
- Real-time and historical analytics are seamlessly integrated.
-
Low Latency
- The streaming-only model is optimized for real-time insights, with sub-10-second latency for customer queries.
Comparison: Kappa vs. Lambda Architecture
| Feature | Kappa Architecture | Lambda Architecture |
|---|---|---|
| Processing Modes | Unified streaming and historical | Separate batch and streaming |
| Technology Stack | Single stack | Multiple technologies |
| Complexity | Simplified | Higher complexity |
| Latency | Lower | Higher |
| Historical Analytics | Stream reprocessing | Batch tools (e.g., Hadoop) |
| Scalability | Optimized for real-time | Better for large batch data |
Validating Success
Twitter rigorously validated the Kappa pipeline’s performance by comparing real-time and historical counts:
- Deduplication Accuracy: Validated using BigQuery to compare raw and deduplicated events.
- Performance Metrics:
| Metric | Improvement |
|---|---|
| Latency | Reduced significantly compared to Heron. |
| Throughput | Achieved stable high-traffic handling. |
| Event Loss | Virtually eliminated through deduplication. |
Limitations of Kappa Architecture
- Batch Data Processing: Kappa is less efficient for large-scale historical analysis compared to batch systems like Hadoop.
- Performance Requirements: High-speed processing engines are necessary to handle both real-time and historical data effectively.
Conclusion
By transitioning to Kappa Architecture, Twitter achieved:
- Low latency with high accuracy.
- Enhanced scalability and stability.
- Simplified operations, resulting in substantial cost savings.
For organizations managing streaming data, the Kappa Architecture offers a powerful solution, combining simplicity, flexibility, and performance. Embracing this architecture can unlock real-time insights and streamlined operations, making it a compelling choice for modern analytics.
Sources
