System Architecture, Databases, and Scalability
A quick short guide on single vs. multi-server setups, database replication, load balancing, and scalability methods like vertical and horizontal scaling.

In this series of blog posts, we’ll explore concepts in system architecture, breaking them down into bite-sized to go over them in under 5 minutes. Today we will be starting with a comparison of single-server and multi-server setups, database replication, load balancing, and scaling strategies. These foundational concepts are key to understanding modern system design and optimizing performance, reliability, and scalability.
Single Server Setup
A single server setup consolidates all functionalities—application logic, database management, and file storage—into one server. This setup is common in small-scale applications or during the initial development phases. Its simplicity and cost-effectiveness make it attractive for startups or personal projects. However, it comes with inherent limitations, such as a lack of scalability and resilience. With all components dependent on a single server, any failure can lead to a complete system outage.
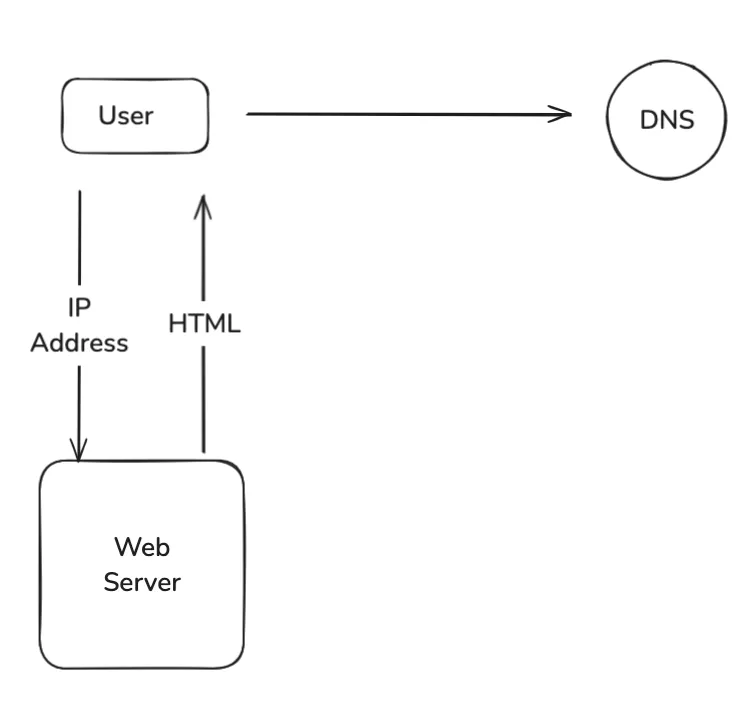
Multi-Server Setup
In contrast, a multi-server setup distributes functionalities across different servers, improving scalability and fault tolerance. For instance, a web server might handle user requests, while a separate database server manages data storage and retrieval. While this approach is more expensive and complex to maintain, it offers significant advantages, such as enhanced performance and the ability to handle higher traffic volumes without compromising system availability.
How Websites Work
Understanding how websites function sheds light on key architectural elements. The process begins with the Domain Name System (DNS) resolving human-readable domain names into machine-readable IP addresses. The browser then retrieves the IP address, enabling it to send HTTP requests to the server. Upon receiving the request, the server responds with content like HTML for web applications or JSON for mobile apps. This seamless process is fundamental to accessing modern web and mobile services.
Traffic Sources
Web and mobile applications have distinct characteristics. Web applications rely on server-side languages like Java or Python for business logic and client-side languages like HTML and JavaScript for user interfaces. In contrast, mobile applications often use lightweight protocols such as HTTP and JSON for efficient data exchange, ensuring responsiveness and usability.
Choosing the Right Database
Database selection plays a critical role in system performance and scalability. Relational databases (SQL) are ideal for structured data and complex queries, while NoSQL databases excel in handling unstructured data and scaling horizontally. Cloud databases offer managed, scalable solutions for dynamic workloads, and data warehouses are optimized for analytics and reporting. Choosing the appropriate database type depends on the specific use case, such as transactional processing versus analytical queries.
Vertical Scaling vs Horizontal Scaling
Scaling strategies are vital to system growth. Vertical scaling involves adding resources (e.g., CPU, memory) to a single server, offering simplicity but limited scalability. Horizontal scaling, on the other hand, entails adding more servers to distribute the workload, providing virtually unlimited scalability but requiring architectural adjustments. Balancing cost, performance, and implementation complexity is crucial when deciding between these approaches.
Vertical Scaling vs Horizontal Scaling
| Aspect | Vertical Scaling | Horizontal Scaling |
|---|---|---|
| Definition | Adding resources to a single server. | Adding more servers to the system. |
| Ease of Implementation | Simple to implement. | Requires architectural changes. |
| Scalability | Limited by hardware. | Virtually unlimited. |
| Cost | High per server. | Economical at scale. |
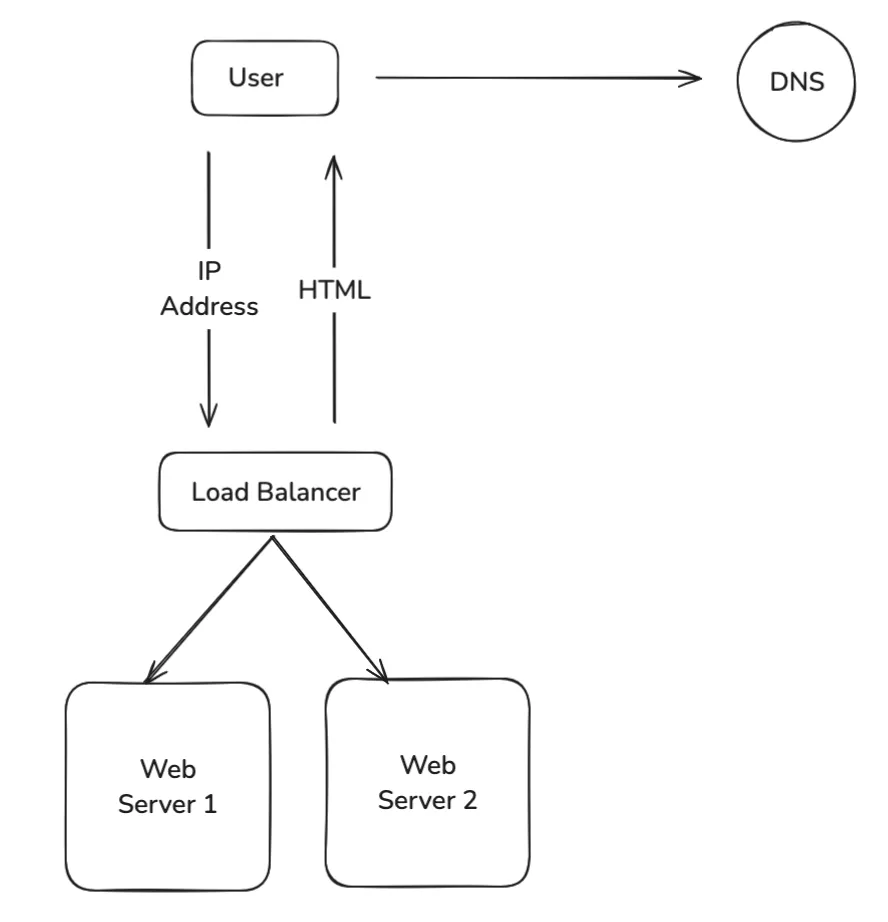
Load Balancers
Load balancers ensure even distribution of incoming traffic across servers, enhancing system performance and availability. They redirect traffic from failed servers and accommodate additional servers for scalability. Common types include hardware load balancers for high performance, software load balancers for cost-efficiency, and cloud load balancers for managed flexibility. Popular algorithms such as Round Robin, Least Connections, and IP Hash determine how traffic is routed, depending on specific requirements.
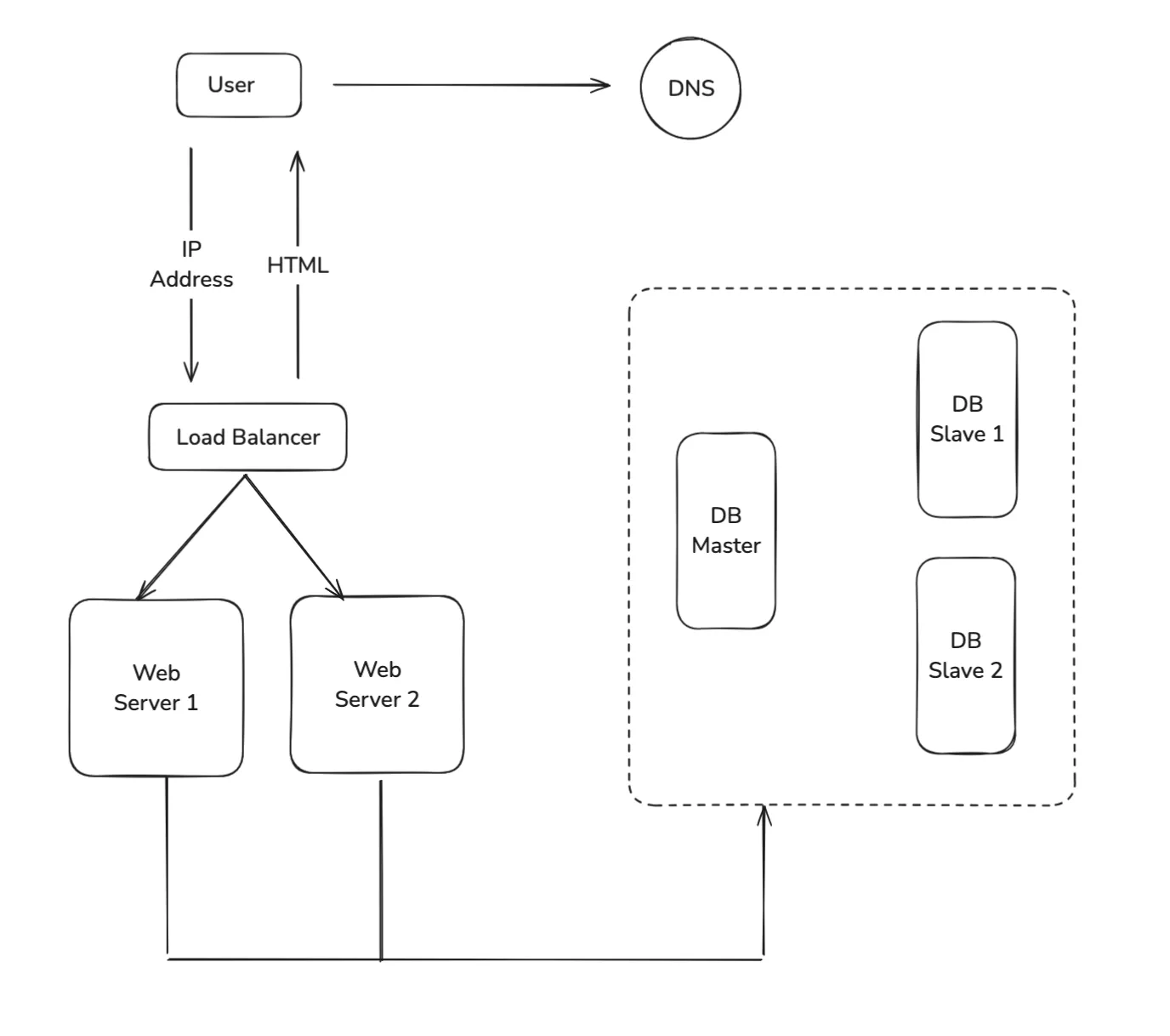
Database Replication
Database replication improves availability, consistency, and scalability by duplicating data across multiple servers. Master-slave replication is ideal for read-heavy workloads, while master-master replication supports both read and write operations, boosting fault tolerance. Replication strategies can be synchronous, prioritizing consistency, or asynchronous, focusing on performance. Despite its benefits, challenges like replication latency and conflict resolution require careful management.
Upcoming Posts
Future posts will explore these topics in more detail, including database optimization, cloud-native architectures, and real-world case studies. Stay tuned for deeper insights into building robust system architectures.
