How Image Generation Works in ChatGPT‑4o
ChatGPT-4o (GPT-4 “Omni”) is OpenAI’s multimodal version of GPT-4 released in 2024. Unlike earlier GPT models, GPT-4o can handle text, images, and audio as inputs and outputs within a single unified model.

ChatGPT-4o (GPT-4 “Omni”) is OpenAI’s multimodal version of GPT-4 released in 2024. Unlike earlier GPT models, GPT-4o can handle text, images, and audio as inputs and outputs within a single unified model.
This means ChatGPT-4o can not only chat via text but it can also generate images as part of the conversation. In the following blog series, we’ll break down how ChatGPT-4o’s image generation works from the underlying technologies and model architecture to the training process, prompt-to-image pipeline, and its capabilities and limitations. We’ll also compare it to systems like DALL·E 2 and Midjourney, and discuss what the future might hold for such multimodal models.
What is ChatGPT‑4o and How Does It Differ from Earlier Versions?
ChatGPT-4o is OpenAI’s flagship multimodal AI model, first announced in mid-2024
It represents a big leap from earlier models in several ways:
-
Multimodal Inputs & Outputs: GPT-3.5 and the initial GPT-4 were primarily text-based. GPT-4 had some vision input capabilities (for example, describing an image), but it could not generate images as output. In contrast, GPT-4o accepts any combination of text, images, or audio as input, and can produce text, audio (spoken words or sounds), and crucially, images as outputs . This makes interaction with GPT-4o more natural and flexible, you can ask it to draw what you describe, or have a conversation mixing words and pictures.
-
Integration vs. Separate Tools: Previously, creating images via ChatGPT meant using a separate model like DALL·E. ChatGPT-4o’s image generator is natively integrated. There’s no hand-off to an external tool, the image is generated directly by the GPT-4o model as part of the chat. This tight integration lets GPT-4o leverage its vast language understanding and context when creating images
In practical terms, GPT-4o “knows” what has been discussed in the chat and can use that context or knowledge base when drawing an image, something earlier GPT models + DALL·E combinations couldn’t do as seamlessly.
- World Knowledge and Reasoning in Images: GPT-4o retains GPT-4’s powerful language and reasoning abilities, and applies them to image generation. For example, it has extensive knowledge of the world – historical events, scientific concepts, pop culture, etc. and can use that to create accurate or contextually relevant images. One OpenAI product lead explained that “the model brings world knowledge to the equation, so when you ask for an image of Newton’s prism experiment, you don’t have to explain what that is to get an image back.”
In other words, GPT-4o already understands concepts like “Newton’s prism experiment” or “ancient Roman architecture” from its training, and can draw them without needing very explicit prompts.
- Faster and More Efficient: Despite its multimodal complexity, GPT-4o was engineered to be faster and more efficient than the original GPT-4 for many tasks. OpenAI reports that GPT-4o can respond to voice input in around ~300 ms (comparable to human conversation speed)
In the text domain, GPT-4o matches the performance of GPT-4 Turbo while being 50% cheaper to run. Microsoft’s Azure team also noted GPT-4o is “engineered for speed and efficiency,” able to handle complex queries with fewer resources. Generating a detailed image is still slower than generating text – more on image latency in the following blog, but overall the model’s design focuses on making multimodal AI practical to use in real time.
Next, let us look at the core technologies that make this possible.
Core Technologies Behind Image Generation in ChatGPT‑4o
Under the hood, GPT-4o’s image generation builds on two major strands of AI technology: transformer-based language models and generative image models. ChatGPT-4o effectively combines these technologies into a single system.
- Transformer Networks: The transformer architecture (which powers GPT models) is fundamental to GPT-4o. Transformers excel at processing sequences (like words in a sentence) and learning long-range dependencies. GPT-4o uses transformers to understand the text prompt and conversational context, and also to help generate images. In fact, GPT-4o treats image creation somewhat like a language problem as we’ll see, it generates images by producing a sequence of “visual tokens” using a transformer
This means the model uses the same kind of neural network for both reading your prompt and drafting a “sketch” of the image in a step-by-step sequence.
- Autoregressive Generation: GPT-4o employs an autoregressive (AR) approach to image generation. Autoregressive means the model generates content one piece after another, with each step depending on the previous ones. For text, GPT models naturally generate word by word (or token by token). Remarkably, GPT-4o extends this idea to pictures. It generates an image as a sequence of tiny elements or tokens, one after the other, rather than all at once. This is very different from most other AI image generators. For instance, DALL·E 2 and Stable Diffusion use diffusion models, which generate the entire image gradually by refining random noise, rather than drawing it piecewise. GPT-4o instead “writes out” the image like text, which is a novel approach in the image domain
Think of drawing a picture pixel by pixel from left to right and top to bottom. That’s the autoregressive method, versus diffusion, which is like developing a photo where the whole image emerges from a blur/noise simultaneously.
-
Diffusion Models : Even though GPT-4o doesn’t rely solely on diffusion, it still uses diffusion as part of its architecture – specifically as a decoder to render the final image from the sequence of tokens. OpenAI hinted at this hybrid approach with a sketch on a whiteboard: _“tokens -> [transformer] -> [diffusion] -> pixels”_
-
Latent Image Representations: To make autoregressive image generation feasible, images are typically represented in a compressed form (often called latent space). GPT-4o doesn’t draw millions of pixels one by one – instead it likely uses a discrete code or tokens that represent patches or sections of an image. This is similar to how earlier models like DALL·E 1 or VQGAN worked, where an image might be broken into a grid and each tile is represented by a code from a learned “vocabulary” of image patterns. By using these visual tokens as an intermediate representation, GPT-4o can generate an image step-by-step at a higher level than raw pixels. (For example, one token might correspond to a 16×16 pixel patch with a certain texture.) This drastically reduces the sequence length needed. The diffusion decoder then translates those tokens into the final high-resolution image. OpenAI hasn’t published the exact details of their encoder, but the phrase “model compressed representations” on their whiteboard suggests they indeed use a form of learned compression for images.
-
Multimodal Integration: GPT-4o’s core innovation is integrating these technologies into one model that is trained on multiple modalities together. It is not just a language model controlling a separate image model, it’s a unified system. During training, GPT-4o learned from datasets that contained text and images together, allowing it to build joint text–image representations. This means the model understands, for instance, that the word “cat” is related to images of furry four-legged animals, and even more complex relationships (like how a caption corresponds to parts of an image). The model’s architecture likely includes mechanisms for cross-modal attention, so it can align textual descriptions with visual features. The end result: GPT-4o has a sort of “visual imagination” connected to its language understanding. It can start with language and imagine an image, or look at an image and describe it in language, using the same neural
By training on text and images together, the model has learned to connect words with visuals in a meaningful way.
Model Architecture Used for Image Generation
The architecture of GPT-4o’s image generation system can be understood as a two-stage pipeline within one model. It works roughly like this: (1) a transformer network acts as an image planner, generating a sequence of latent image tokens based on the prompt, and (2) a diffusion model acts as an image renderer, converting those tokens into the final image.
-
Multimodal Transformer Encoder (Text Encoder): When you provide a text prompt, GPT-4o first processes the prompt (and any preceding conversation) through a transformer encoder. This is similar to how any GPT model reads and understands text. The output is a set of text embeddings – basically numerical representations capturing the meaning of your request. If you also provided an input image (for example, “here is a sketch, make an image from it”), the model would encode that too using vision-processing layers, but for now let’s assume the prompt is just text describing an image to create.
-
Autoregressive Image Token Generator (Transformer Decoder): Next, GPT-4o’s generative capability comes into play. The model extends the transformer to start generating visual tokens that represent the image that fulfills the prompt. It does this autoregressively – one token at a time – almost like it’s writing a very long sentence, except the “sentence” is describing an image in an internal code. These visual tokens might correspond to small patches of the image or other latent elements. Importantly, they are generated in a structured order (for example, scanning left-to-right, top-to-bottom). This ordering ensures spatial coherence – the model is essentially laying out the image from one corner outward. By the end of this stage, GPT-4o has produced a compressed visual plan of what the image should look like. You can think of this as the model sketching the outline and contents of the image in an abstract form. (It’s a bit like it wrote a description in a secret visual language that only it and the decoder understand.)
-
Diffusion Decoder (Image Synthesis Module): Now comes the step of turning that plan into an actual picture. GPT-4o feeds the sequence of visual tokens into a diffusion-based image decoder. The decoder works group-wise or patch-wise across the image: it divides the image space into chunks (for example, horizontal stripes or blocks) and generates pixels for each chunk using a diffusion process, one chunk at a time. Diffusion here means it starts each chunk as random noise and then iteratively refines it into a clear image patch, guided by the information from the visual tokens and the original text prompt. At each refinement step, the decoder uses cross-attention to consult the “visual plan” tokens and the _text embeddings_ . In essence, as it paints each portion of the image, it checks “What was I supposed to draw here according to the plan? And what did the user ask for again?” This ensures that the final rendered image faithfully follows the layout and details intended by the transformer. The decoder proceeds chunk by chunk until all parts of the image are generated, and then stitches them together into one complete image . The result is the full-resolution image output.
It’s worth noting that while we describe two stages, GPT-4o is trained as a single model that encompasses this whole pipeline. During training, the model learns to go from prompt to tokens to image in a seamless process. So, GPT-4o isn’t simply two separate AI models hacked together; it’s a unified architecture. In fact, OpenAI initially considered a single giant transformer that directly generates pixels, but that would have been extremely computationally heavy and inefficient (because images are much larger data than text). Their solution was exactly this: “model compressed representations” of images and “compose an autoregressive prior with a powerful decoder”. In other words, use a transformer to generate a compressed image representation (the prior) and then a decoder (diffusion) to produce the final pixels – which is what we described above.
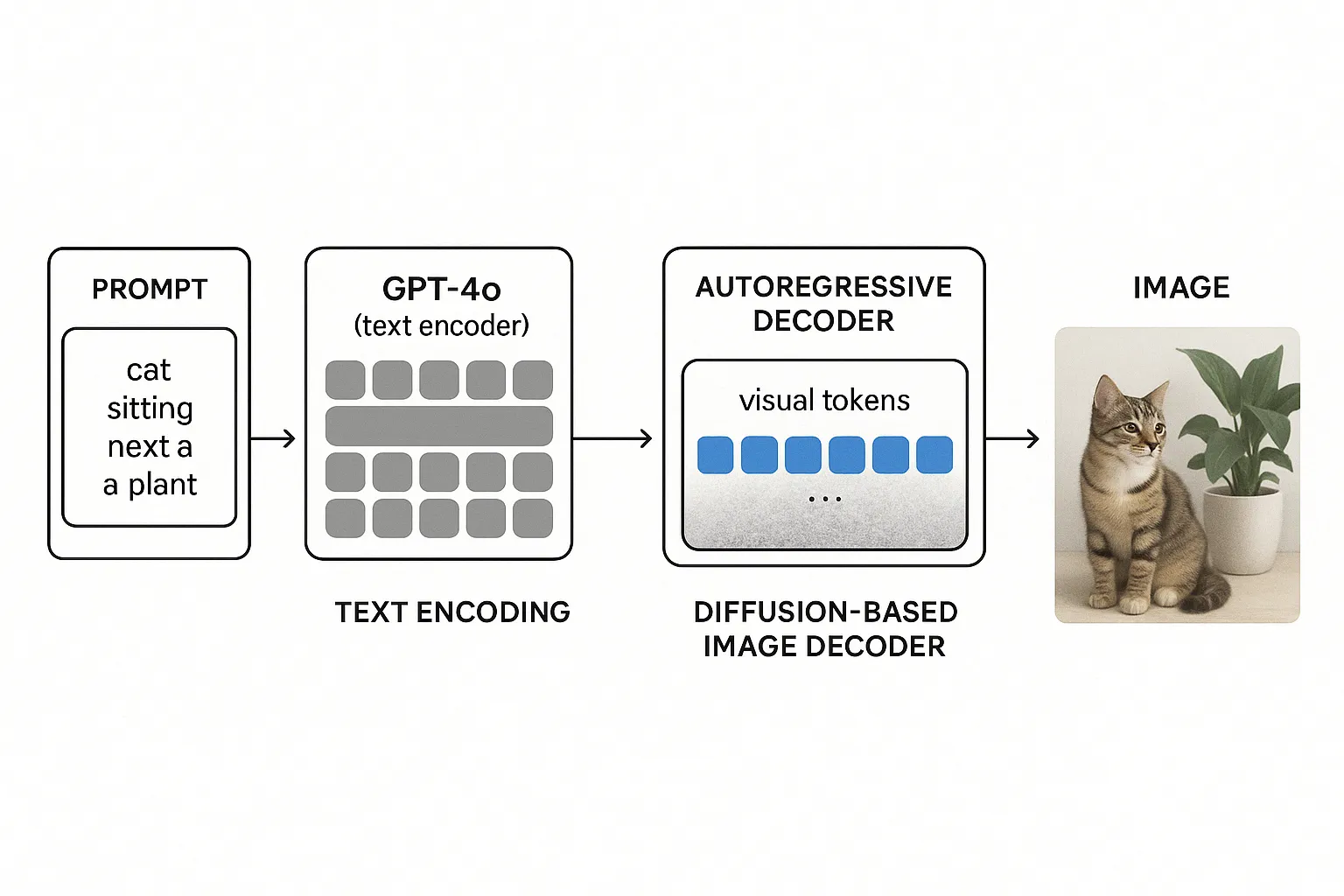
A simplified view of ChatGPT-4o’s image generation pipeline. The user’s text prompt is first encoded by GPT-4o’s transformer (text encoder) into embeddings. The model’s autoregressive decoder then generates a sequence of visual tokens (a latent “blueprint” of the image) based on those embeddings. Finally, a diffusion-based image decoder uses the visual tokens (and text context) to render the image, producing the final picture piece by piece.
This architecture is quite innovative. By doing image generation in a transformer framework, GPT-4o gains some unique advantages. Notably, it can maintain exceptional alignment between the image and the prompt. Because the same model “planned” the image and has read the prompt, it tends to follow instructions very literally and consistently. For example, early users and OpenAI researchers found GPT-4o is much better at correctly binding attributes to objects than traditional diffusion models. An image model with poor “binding” might scramble details, ask for “a blue star and a red triangle” and it might produce a red star and a blue triangle, or forget one of the shapes. GPT-4o’s architecture, however, allows it to correctly bind attributes for many objects at once (OpenAI reports 15–20 distinct items in a scene can be handled without confusion, compared to 5–8 items for most diffusion models). This comes from the transformer’s strength in handling complex, structured information.
To summarize the architecture: GPT-4o uses a multimodal transformer to understand the prompt and auto regressively outline the image, and a diffusion model to paint the image from that outline. This “outline” is not visible to the user, but it’s the secret sauce that lets GPT-4o be so precise in what it draws. Now, how was such a model trained? Let’s explore the training techniques and data that made this possible.
Reference
Hello GPT-4o openai.com
From Prompt to Picture: How ChatGPT-4o’s New Image Generation Works medium.com
OpenAI rolls out image generation powered by GPT-4o to ChatGPT theverge.com
Introducing GPT-4o: OpenAI’s new flagship multimodal model now in preview on Azure azure.microsoft.com
Introduction to GPT-4o Image Generation – Here’s What You Need to Know learnopencv.com
