Data Storage & Database Systems
Choosing the right data storage is key in modern app development. In this blog, we’ll break down core concepts like relational vs. non-relational databases, data modeling, the CAP theorem, and scaling strategies such as indexing, replication, and sharding.
Data Storage & Database Systems
In modern application development, choosing the right data storage and database systems is critical. In this blog, we’ll explore core concepts around how data is stored and managed. We’ll compare relational vs. non-relational databases, discuss data modeling and schema design considerations, dive into the CAP theorem and consistency models, and examine indexing, replication, and sharding strategies for scaling.
Relational vs. Non-Relational Databases
Relational databases (SQL databases) and non-relational databases (NoSQL databases) are two broad categories of data stores. Each comes with its own philosophies, strengths, and trade-offs. Let’s break down what they are and how they differ:
-
Relational Databases (SQL): These store data in a structured format using tables with rows and columns. Tables can relate to each other via foreign keys, hence the name “relational.” Data is manipulated with Structured Query Language (SQL). Relational databases enforce a rigid schema – you define tables and columns (with data types) upfront, and every row must adhere to that schema. They are known for ACID compliance, meaning they ensure Atomicity, Consistency, Isolation, and Durability of transactions (all-or-nothing transactions, consistent state, isolated concurrent operations, and durable storage of commits). Classic examples include PostgreSQL, MySQL, Oracle, and SQL Server.
-
Non-Relational Databases (NoSQL): This is an umbrella term for databases that do not use the traditional table schema. They can store data as documents (e.g. JSON documents in MongoDB), key-value pairs (like Redis or DynamoDB), wide-column stores (like Cassandra), or graphs, etc. NoSQL databases typically offer a flexible schema, allowing storage of unstructured or semi-structured data without predefined tables. They often sacrifice some ACID guarantees in favor of scalability and performance, embracing the BASE philosophy (“Basically Available, Soft state, Eventual consistency”). NoSQL systems are designed with horizontal scaling in mind – meaning they can distribute data across many servers more easily than the typically vertically-scaled SQL systems.
When to choose which? Relational databases shine when data integrity and complex querying (JOINs across multiple tables) are required. They ensure consistency and are ideal for structured data – for example, a banking system where transactions must follow strict rules. Non-relational databases excel for flexibility and scale, especially with big data or fast-changing schemas – for instance, storing JSON configurations, user activity logs, or caching results. Many modern applications actually use a mix: a relational database for core business data and a NoSQL store for specific needs (caching, full-text search, analytics, etc.).
To visualize the difference, consider an example domain: an e-commerce customer and their orders, addresses, product reviews, etc. In a relational model, this data would be normalized into separate tables (Customer, Order, Address, Product, Review), linked by keys. In a document model, all relevant info for a customer might be stored in a single JSON document. Let’s see what that looks like.
Relational data model: information is split into multiple tables (Customer, Order, Address, Product, Reviews), with relationships via primary/foreign keys. Each green box represents a table, and arrows indicate how a customer record links to their orders, addresses, etc. Data is organized in a structured, normalized way, which avoids duplication and ensures consistency across related records. Queries can join these tables to gather full customer information when needed.
Document-based data model: all information related to a customer (orders, product details, reviews, addresses) is embedded within a single JSON-like document. This denormalized approach stores the customer’s data in one place, which can simplify read operations – one query can fetch the entire customer document without needing multiple JOINs. The trade-off is potential data duplication (e.g., product details repeated in each order) and more complex updates if, say, a product name changes, since many documents might need modification. However, it aligns well with object-oriented programming (data comes out already aggregated) and can be more natural for certain use cases.
Relational vs. Non-Relational: Practical Example (PostgreSQL vs. MongoDB)
To make this concrete, let’s implement a simple order tracking scenario in both a SQL and a NoSQL database. Our scenario: we have Customers who place Orders. Each Order has a product name and amount. In a relational design (PostgreSQL) we use separate tables and a foreign key; in a document design (MongoDB) we embed orders inside the customer document.
PostgreSQL (Relational) approach: We’ll create two tables – customers and orders – and relate them:
-- PostgreSQL: Define tables
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
name TEXT
);
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
customer_id INT REFERENCES customers(id), -- Foreign key to customers
product TEXT,
amount INT
);
-- Insert a customer and two orders for that customer
INSERT INTO customers (name) VALUES ('Alice');
-- Assuming the new customer got ID = 1
INSERT INTO orders (customer_id, product, amount) VALUES
(1, 'Laptop', 1200),
(1, 'Mouse', 25);
-- Query: fetch customer info with their orders using a JOIN
SELECT c.name, o.product, o.amount
FROM customers c
JOIN orders o ON o.customer_id = c.id
WHERE c.name = 'Alice';
When we run the SELECT query, the database performs a join between the tables to gather Alice’s orders. The result might look like:
name | product | amount
-------+---------+--------
Alice | Laptop | 1200
Alice | Mouse | 25This approach ensures data is normalized (customer info stored once in customers table, orders in orders table). If Alice’s name changes, we update one row. But retrieving all orders requires a join.
MongoDB (Document) approach: We’ll store customer and orders together as one document in a customers collection. Using the Mongo shell (JavaScript syntax):
// MongoDB: Insert a customer document with embedded orders
db.customers.insertOne({
name: "Alice",
orders: [
{ product: "Laptop", amount: 1200 },
{ product: "Mouse", amount: 25 }
]
});
// Query the customer by name (the orders come along as embedded data)
const alice = db.customers.findOne({ name: "Alice" });
printjson(alice);
The stored document for Alice would resemble:
{
"_id": ObjectId("..."),
"name": "Alice",
"orders": [
{ "product": "Laptop", "amount": 1200 },
{ "product": "Mouse", "amount": 25 }
]
}A single findOne returns Alice’s record with all her orders embedded. There’s no need to join multiple collections in this case, since all relevant data is in one place. This denormalized design makes reads very efficient (one lookup for all data). However, if an order needed to reference a product from a separate collection, or if orders were large in number, we might consider storing them separately or using references. NoSQL allows both embedded documents and references; the choice depends on access patterns (embed if data is usually fetched together, separate if data is reused across many records or frequently updated independently).
Takeaway: Relational vs. non-relational design decisions often come down to joining vs. embedding. SQL uses relations to avoid duplication, while NoSQL may allow duplication to optimize reads. Neither is “better” universally; it depends on the use case. As a developer, consider how your data will be accessed: if you frequently need aggregated data (like a customer and all their info at once), a document model might be simpler. If you need strict consistency and the ability to query data in many ad-hoc ways (filtering, joining on various fields), a relational model is powerful and expressive.
Data Modeling and Schema Design
Data modeling is the process of defining how you structure your data — which entities (tables or documents) you have, what fields they contain, and how they relate. Schema design refers to this structure definition. Good schema design is essential for both correctness and performance. Let’s explore some principles for both relational and non-relational databases:
Relational Modeling & Normalization
In a relational database, schema design often follows the principles of normalization. This means structuring your tables such that each fact is stored only once, minimizing redundancy
. For example, instead of storing a customer’s address in every order row, you’d have a separate Address table and reference it via an address_id. Normalization (through normal forms like 1NF, 2NF, 3NF, etc.) helps eliminate anomalies when inserting, updating, or deleting data.
The process typically involves:
-
Identifying entities (e.g. Customer, Order, Product, etc.) and creating separate tables for each.
-
Choosing primary keys for each table (unique identifiers).
-
Establishing relationships using foreign keys (e.g. Order table has a foreign key customer_id referencing Customer table).
-
Ensuring consistency with constraints (data types, NOT NULL, UNIQUE, etc. to enforce valid data).
The benefit of a well-normalized relational schema is data integrity – you cannot accidentally have mismatched or duplicate info easily. It’s also often easier to update one piece of data (change a product name in one place and all orders reflect it via the join). The downside can be performance on complex queries, since retrieving a complete picture may require multiple JOIN operations across tables. Proper indexing (which we’ll discuss later) and careful query planning mitigate this in many cases.
NoSQL Modeling & Denormalization
Schema design in a NoSQL (document) database is more about optimizing for your query patterns. Since NoSQL allows flexible schema, you can choose to embed or separate data based on what queries you need to run. The common mantra is “design for the use case.” If our application always needs to fetch a user and their recent activity together, putting them in one document makes sense. If two pieces of data are almost always accessed independently, they might go in separate collections.
Key considerations for NoSQL schema design:
-
Embedding vs Referencing: To embed or not to embed is a central question. Embedding (nesting sub-documents or arrays) can eliminate the need for joins and make reads very fast (all data in one place)
However, embedding can lead to large documents and duplication. Referencing (storing something like a foreign key) keeps data normalized (like a relational model) but then your application might have to do multiple queries (one to get the main document, another to get referenced data) or use $lookup (Mongo’s join-like aggregation) if needed. Generally, embed when data is tightly related and often fetched together; reference when data is reused in many places or frequently updated on its own.
-
Schema flexibility: MongoDB does not require all documents in a collection to have the same structure, but having a generally consistent structure is still important for sanity and query efficiency. You don’t explicitly declare a schema, but you should still plan what fields will be present. It’s common to include versioning or migration strategies for documents as your application evolves (since adding a new field won’t break the database, but your code might have to handle missing fields in old docs, etc.).
-
Atomicity and transactions: Remember that in many NoSQL databases, operations on a single document are atomic, but multi-document operations are not (unless you use multi-document transactions in MongoDB, which have some limitations). This means if you have a heavily denormalized design (duplicating data), updating that data consistently in many places can be challenging. Sometimes the schema might duplicate read-mostly data but still keep some critical data single-sourced. For instance, you might embed product name and price in an order for quick access, but the authoritative price is in a central product document – if price changes, you might update it in new orders but leave old orders unchanged as a historical record.
Example – Modeling Blog Posts & Comments:
-
Relational Schema: A
poststable and acommentstable, where each comment has apost_idforeign key to its post. To fetch a post with comments, you’d join or do two queries. This is normalized (no duplicate comment data) and each comment is an independent row. -
Document Schema: A
postscollection where each post document contains an array of comment sub-documents. Fetching a post with its comments is a single query returning one document. This is denormalized (comments are stored inside a post). Adding a comment means updating the parent post document (which, if comments array grows large, might be less efficient).
There’s no one-size-fits-all answer – the choice depends on scale and access patterns. In a high-throughput system, you might even combine approaches: store data in a normalized SQL database for consistency, and also maintain a denormalized cache or search index for fast reads. The important thing is to think about how your data will be used and design accordingly.
CAP Theorem and Data Consistency Models
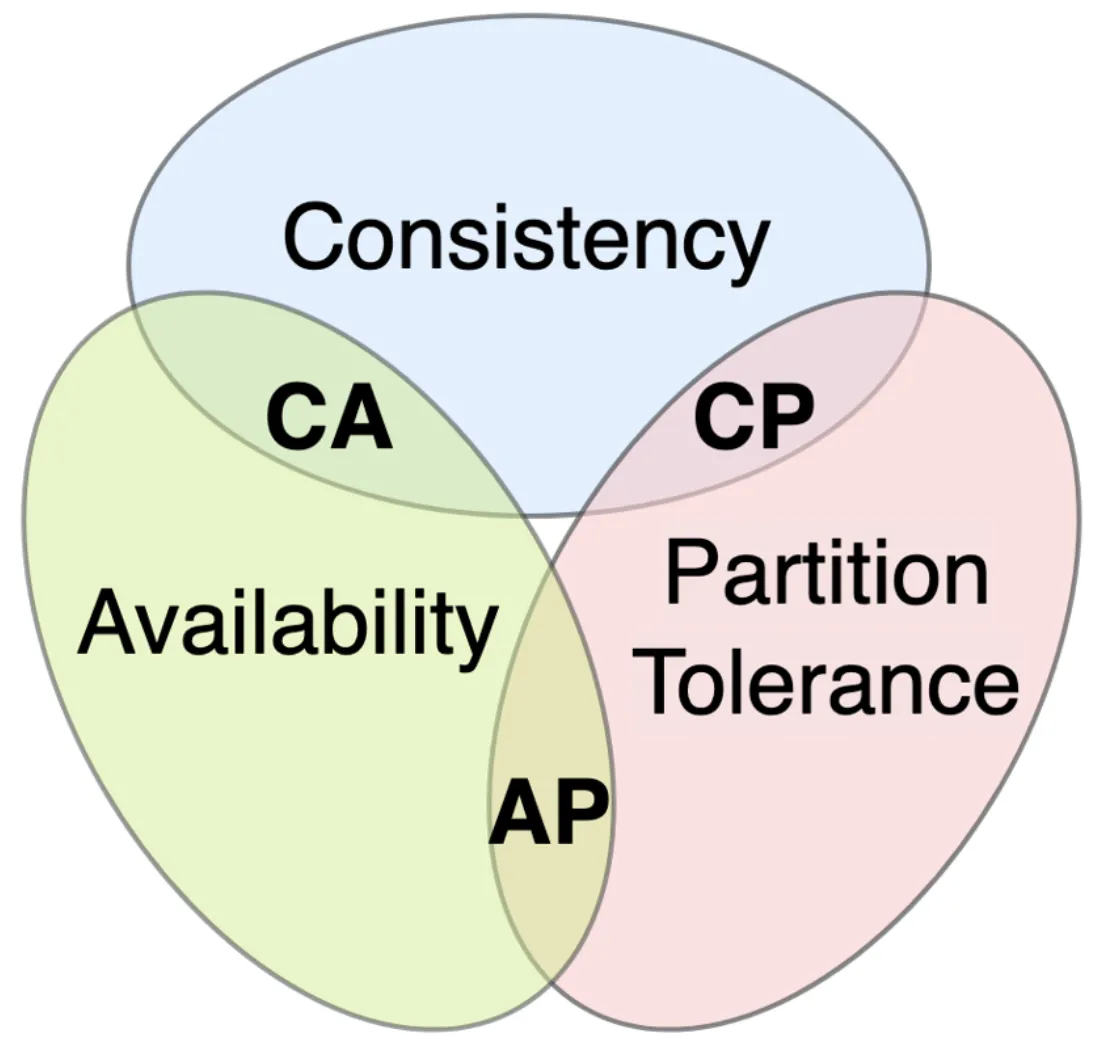
When designing distributed database systems, you’ll encounter the famous CAP theorem and various consistency models. Let’s demystify CAP and what consistency means for your app.
CAP Theorem in a nutshell: CAP stands for Consistency, Availability, Partition tolerance. The theorem (Brewer’s theorem) states that in any distributed data system, you can only guarantee two out of three of these properties. If a network partition (a break in communication between nodes) occurs, the system has to choose between being consistent or available
-
Consistency (C): Every read receives the most recent write or an error. In other words, all nodes see the same data at the same time. If you write something and then read it (from any node), you’ll get that write (no stale data). Under partition, a consistent system will refuse reads/writes that can’t be guaranteed (it might return an error rather than stale data).
-
Availability (A): Every request receives some (non-error) response, even if some nodes are down. An available system continues to operate and return responses (possibly older data) despite failures. Under partition, an available system will still process requests, but can’t guarantee those requests see the latest data.
-
Partition Tolerance (P): The system continues to work despite arbitrary network partitions . This is generally not optional – in a distributed system, network failures will happen, so partition tolerance is usually a given requirement. It means the system can sustain communication breakages between nodes and still function in some capacity.
CAP Theorem Venn Diagram: In a network partition, a distributed system must choose either consistency (CP) or availability (AP). CA (consistency + availability without partition tolerance) is only possible when the system is not distributed or the network is perfectly reliable – a single-node database can be CA since there’s no partition to tolerate. But in a cluster, once a partition occurs, you face a trade-off. For example, a CP system will prefer consistency: it may refuse to serve requests on a partitioned node (sacrificing availability) to avoid serving stale data. An AP system will prefer availability: it continues to serve requests on all nodes (even partitioned ones), accepting that data might not be consistent across nodes until the partition heals.
Most distributed databases are either CP or AP under the presence of partitions . Let’s connect this to real databases:
-
Traditional SQL databases (when run on a single node or with synchronous replication) lean towards Consistency over Availability. If they cannot confirm a write on the replicas or the single node is down, they’d rather error out (be unavailable) than allow inconsistent data. For example, a PostgreSQL primary with synchronous replicas: if it can’t reach a replica to replicate a transaction, it may block progress (trading availability for consistency). These systems assume partitions are rare and correctness is paramount. In CAP terms, they tend to be CP in a distributed setup (or CA if you consider a single-node as no partition scenario).
-
Many NoSQL databases (especially those designed for distributed scale, like Cassandra or Amazon Dynamo-inspired systems) lean towards Availability over strict consistency. They’ll allow reads/writes on partitioned nodes and reconcile differences later (this is called eventual consistency). For instance, Cassandra is often cited as an AP system: it is designed to always accept writes (to any replica, even if others are down) and gossip the changes to others asynchronously. MongoDB by default (with a single primary-secondary setup) is CP – if the primary is partitioned away from secondaries, it steps down and won’t accept writes until a new primary is elected (so it sacrifices availability briefly to ensure only one primary accepting writes). However, MongoDB can be tuned with write concerns and read preferences to offer tunable consistency — you could choose to read from secondaries (potentially stale, for more availability) or only primary (for consistency). So some databases blur the lines and let you configure how much C vs A you want.
Consistency Models (Strong vs Eventual): Outside of the strict CAP context, in practical terms we talk about how up-to-date the data is on reads in a distributed system:
-
Strong Consistency: After you write data, any subsequent read (to any replica) will return that data. This is equivalent to the CAP “consistency” guarantee. It often requires things like quorum writes/reads or single-leader architectures where reads go to the leader. Example: in a strongly consistent system, when Alice posts a comment and immediately refreshes, she always sees her comment. Google’s Spanner (a globally distributed SQL DB) aims for strong consistency across datacenters using TrueTime (GPS-synchronized clocks) to coordinate — this is hard to achieve but they sacrifice latency for it. Most relational databases provide strong consistency on a single node (or within a primary/leader).
-
Eventual Consistency: After a write, it’s not guaranteed that immediate reads will see it; however, if no new writes occur, eventually all replicas will converge to the last value. In an eventually consistent system, Alice might post a comment and a read from a different replica immediately after might not show it, but after some seconds, all replicas have it. This model is often acceptable in use cases where slight delays are fine (like social media feeds, where if a comment appears a second later, it’s not the end of the world), and it allows higher availability and partition tolerance. DynamoDB, Cassandra, CouchDB, etc., by default are eventually consistent (though many offer tunable consistency where you can request strong consistency at the cost of latency or availability).
There are also models like “Read-your-writes” consistency, “Monotonic reads”, “Session consistency”, etc., which are nuances ensuring certain user expectations (for instance, read-your-writes is a guarantee that your subsequent reads will reflect your writes, even if globally the system is eventually consistent). These are provided by some systems to make eventual consistency a bit more predictable for users. For example, MongoDB’s drivers by default provide read-your-write consistency on the primary by routing your read after a write to the primary, not a secondary.
The key takeaway for a developer is to understand the consistency needs of your application. Do you absolutely need every read to have the latest data (e.g. bank account balance after a transaction)? If yes, design for strong consistency (CP side of CAP, maybe using a relational DB or a strongly-consistent distributed DB). If your app can tolerate slight delays in propagating updates (e.g. a “like” count that might update a few seconds later), you can choose more AP, eventually-consistent systems that might be more available and partition-tolerant. Often, layering strategies like caching (which might serve slightly stale data) or queueing writes can introduce eventual consistency even if your database is ACID – so it’s always a spectrum and a conscious decision.
References:
-
Relational vs. Non-Relational fundamentals
-
Advantages of document model and horizontal scaling
-
ACID transactions and relational guarantees
-
Relational schema example (customer, order, etc.)
-
CAP theorem definitions and trade-offs
-
RDBMS vs NoSQL consistency (ACID vs BASE)
-
Indexing benefits for query performance
-
Replication and sharding explained
-
Combined replication and sharding in practice
-
Cache-aside pattern steps
